
Finalists with the esteemed expert judges
I am incredibly humbled and fortunate to come in 1st place in the inaugural Singapore Nationwide AWS Large Language Models League (LLML) 2024!
I was extremely heartened to have had several individuals reached out to discuss and share their experiences and approaches in tackling this competition. So I wanted to share my personal experiences and lessons learnt. This is quite a long read, so use the table of content to navigate to where you think might be useful or interest you!
Before I start, I am compelled to share the succinct yet insightful writeup by Swee Heng, who was the undisputed 1st place on the preliminary round leaderboard. Check out his QnACrafter which I believe was one of his key success factors!
Competition Modality 🔗
The LLML is a large language model fine-tuning (and part prompt engineering, albeit only in the Grand Finals) competition organised by Amazon Web Services (AWS) team. As the lead up to the competition, Gen-C (a Gen AI Learning Community) partnered with NLB to conduct multiple free 2-hour workshops on using the no-code AWS SageMaker JumpStart to fine-tune LLMs, with the aim of democratising AI and ML. Find out more in Jiawei’s article.
In the preliminary round, participants were allowed unlimited submission of their fine-tuned models. Our fine-tuned models (based off the Llama-3-8B-Instruct model) were pitted against a Llama-3–70B-Instruct model on a total of 49 undisclosed questions in the domain of Singapore culture, with the quality of responses judged by another LLM (both the model judge and the system prompt for judging were not revealed). We scored a win for each question where the LLM judge deemed our fine-tuned model’s response more accurate and comprehensive than that of the 70B model.
In the preliminary round, participants were allowed unlimited submission of their fine-tuned models. Our fine-tuned models (based off the Llama-3-8B-Instruct model) were pitted against a Llama-3–70B-Instruct model on a total of 49 undisclosed questions in the domain of Singapore culture, with the quality of responses judged by another LLM (both the model judge and the system prompt for judging were not revealed). We scored a win for each question where the LLM judge deemed our fine-tuned model’s response more accurate and comprehensive than that of the 70B model.
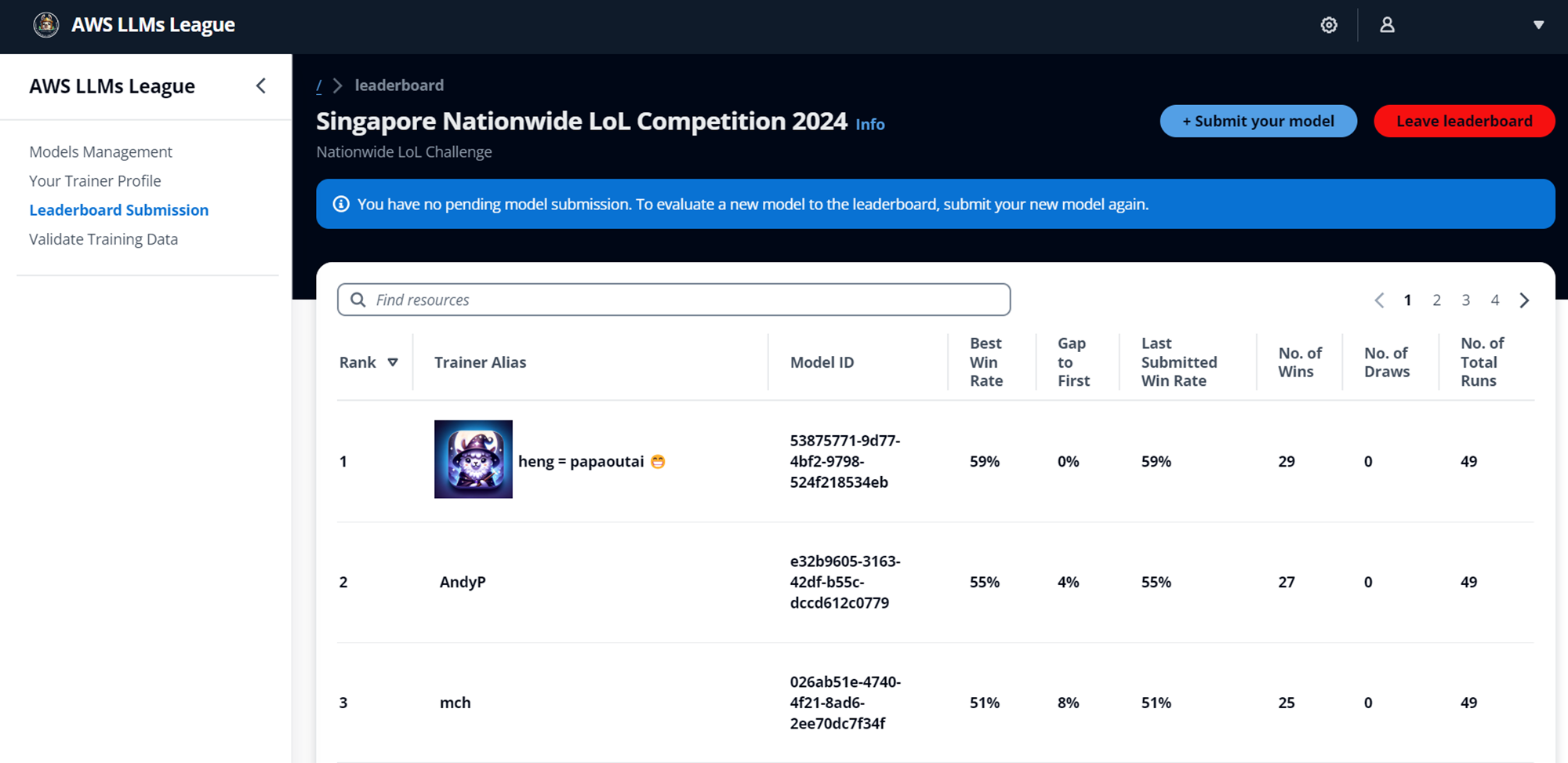
I managed to secure 2nd place on the overall leaderboard in the preliminary round
Of note, it seemed like the win-rate of ~50% ain’t really that high. We were told that the previous AWS LLM Student League had a win-rate of ~90%. I felt that it could be the topic of ‘“Singapore culture” being more challenging (as compared to the student league topic of “Responsible AI”). Due to the cultural nuances in Singapore context and that Singapore-related corpus likely representing a less significant portion of the entire pre-training corpus, it is much more difficult to fine-tune the Llama-3–8B-Instruct model to outperform the 70B. There is a whole lot of literature and research on instruction fine-tuning which I will not go into. It does seem like instruction fine-tuning does not inject new knowledge into the model, but at best brings out its innate knowledge better and adjusts its style.
The top five finalists advanced to the Grand Finale on October 3rd. In the Grand Finale, we faced off against each other over seven questions, judged by a LLM (40%), a panel of five experts (40%), and audience (20%). Besides generating responses using our best fine-tuned models, we also had to craft our own prompts and decide on the temperature and top-P parameters (all within 60 seconds) depending on the nature of each question. Find out more about the Grand Finale in Huy’s article.
My Fine-Tuning Journey 🔗
Before I go into the details, I would like to caveat that my insights are based off my trial-and-error fine-tuning attempts. These are empirical and highly likely not reflect universally optimal approaches nor guarantee results. As to how I came in 1st place, I must emphasise that luck played a very big part. All four other finalists were as good, if not better than I was. This was clearly evident as our scores were neck-to-neck across all the rounds. I certainly hope that when you try the same ‘secret sauce’ as me in the next iteration of the AWS LLML, you will get the same luck!
In the broad scheme of things, given the limited training hours, the key challenge I felt was on balancing the trial-and-error experiments between hyperparameters tuning and dataset selection - which to focus on.
Synthetic Data Generation 🔗
During the workshop, the Gen-C team shared a synthetic data generation app that they built using AWS Partyrock. We were able to ‘clone’ the app, and customise it, such as changing the inference model and tweaking the prompts.
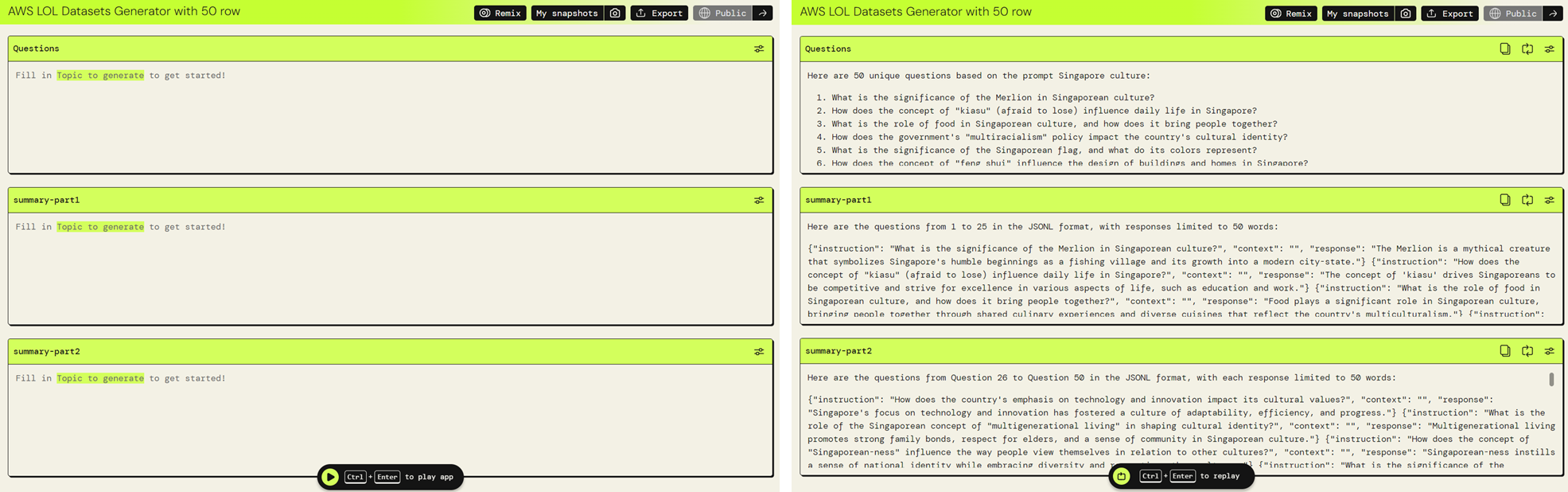
Synthetic data generation using a gen-AI tool built using AWS Partyrock. Credit to Gen-C Community
Using it mainly out-of-the-box, I generated some datasets (starting with around 100 and eventually scaling it up to around 800). As the better inference models in Partyrock were limited to Claude 3 Sonnet and Llama-3.1–70B-Instruct, I then tried refining the responses using ChatGPT-4o.
# simple prompt used to refine the responses generated from Partyrock
<Paste the instruction-context-reponse generated from Partyrock here>
In the above, "instruction" refers to a question and "response" refers to the answer to the question.
Evaluate how accurate and comprehensive the "response" is to the "instruction".
This will be used to fine tune a large language model on Singapore culture.
Replace the "response" with one that is more accurate and comprehensive if required.
Output in the same format, each response on a new line but without any new blank line between responses, in json format.
I did it iteratively using ChatGPT-4o by copying-pasting in batches of 20 instruction-response pairs, so it got pretty tedious. There is an alternative way to do it programmatically using OpenAI API, but at the tradeoff of cost. More on that later.
Hyperparameters Tuning 🔗
Using AWS SageMaker JumpStart, there were some hyperparameters available for fine-tuning. I mainly focused on epoch, learning_rate, lora_r, and lora_alpha.
In the early weeks of the preliminary round, I could not quite figure out if I should focus on hyperparameter tuning or the dataset (both size and quality). It felt like a blind chase, with no real improvement in results - except for a modest score of 20/49 (40%), which brought me into the top 50, as many others seemed to stall at 19/49 (38%).
Below were some of the hyperparameters I tried (although not all 150-ish combinations) and my reflections. Of note, what I did was more like a randomized grid search rather than a exhaustive grid search approach.
epoch: 1 to 5 (with one training iteration using 10)learning_rate: 0.00005, 0.00002, 0.0001, 0.0002, 0.0003 (with one training iteration using 0.001)lora_r: 4, 8, 16, 256lora_alpha: 8, 32, 128, 256, 512
Low-Rank Adaptation (LoRA)
Specifically for the lora_r and lora_alpha combination, I was mainly using lora_alpha being 2x that of lora_r which seemed to be the most commonly suggested ratio, although for some training iterations I tried ratios of 0.5 and 1 based on suggestions from this article on fine-tuning LLMs using LoRA.
Choosing alpha as two times r is a common rule of thumb when using LoRA for LLMs, but I was curious if this still holds for larger r values. In other words, “alpha = 2×rank” really seems to be a sweet spot. However, in this specific combination of model and dataset, where r=256 and alpha=128 (a 0.5-fold scaling) performance is even better… Choosing alpha as two times as large as r may often result in the best outcomes, but it may also not hurt to experiment with different ratios.
I also experimented with changing the target_modules for LoRA fine-tuning from the default of q_proj and v_proj to include k_proj and o_proj but got the worst performance at 3/49 (although it could also be due to over-setting my lora_r and lora_alpha at 256 resulting in overfitting). This was something I was keen to explore further, if not for the lack of training hours.
From that same article and a related article, I gleaned some additional insights that guided my next actions.
Epoch
The takeaway is that multi-epoch training might not benefit instruction finetuning since it can deteriorate the results. I observed the same with the 1k-example LIMA dataset. This performance decline is likely due to increased overfitting, which warrants additional investigation.
Hence I decided to keep my epoch at 1 and learning_rate at 0.0001. I wished there were some sort of control over the learning rate through a scheduler for adaptation to improve model performance, convergence, and stability. I also decided to set my lora_r at 4 (and hence lora_alpha of 8) which were the parameters that gave me the best preliminary result of 40%.\
Importance of dataset
The dataset can be critical… Data quality can be very important.
In the LIMA paper, the researchers showed that a 65B LLaMA model finetuned on only 1000 examples (in a supervised fashion) is not too far behind bigger models like ChatGPT / GPT3.5… So we may conclude that the difference is really in the quality of the training set
Noting the above, I decided to switch focus to the dataset.
Data, Data, and More Data! 🔗
I think like many others, I had limited success using the synthetic data generated from Partyrock, although I believe it could be better if I had spent more effort to customise it.
At the start, I had come across a dataset from the SeaEval team (some of the researchers are actually from A*STAR Singapore!), who introduced a novel pipeline for extracting high-quality, culturally-related instruction tuning datasets from vast unstructured corpora. They open-sourced a Singapore-context instruction-response dataset that was created using GPT-4. There were about 26k data points which seemed perfect for what we need to fine-tune our model for the competition!
I had tried using this dataset very early on, but ambitiously used the full dataset and set epoch = 3 which unsurprisingly exhausted all my remaining training hours (given 3 hours at the start) before the fine-tuning could complete. Thankfully, along the way, we were given additional training hours after we attended the clinic sessions conducted by Gen-C community.
Lessons learnt. So I re-strategized and decided to adopt a more cautious approach with the dataset size. The natural question is how big would a dataset be considered enough? That’s when I came across this paper “LIMA: Less Is More for Alignment” which showed that:
fine-tuning a strong pretrained language model on 1,000 carefully curated examples can produce remarkable, competitive results on a wide range of prompts
Next question - how can I curate good quality data? Thankfully another paper came to the rescue. This paper “Long Is More for Alignment: A Simple but Tough-to-Beat Baseline for Instruction Fine-Tuning” found that:
the extremely simple baseline of selecting the 1,000 instructions with longest responses - that intuitively contain more learnable information and are harder to overfit - from standard datasets can consistently outperform these sophisticated methods
Afternote: came across another paper “Rethinking Data Selection at Scale: Random Selection is Almost All You Need” that said:
selecting data by token length can stably obtain a relatively high training benefit, reduce the uncertainty caused by randomness, and reduce costs. This approach is particularly beneficial for base language models which generally have limited capabilities (Llama-3), as they tend to derive the most significant benefits from training on longer texts
With these, I came up with an approach: choose the top 1,000 data points with the longest response token length (which I dub as SeaEval-1k) from the SeaEval-26k dataset. Using this dataset, I scored a breakthrough at 23/49 (46%). I then tried with the top 2,000 data points but it gave me the same result.
Following some success, I had an inclination that the dataset was probably of good enough quality, I then tried a fresh iteration of training using the full 26k dataset (albeit conservatively setting epoch = 1 this time round). That got me to a new high of 26/49 (53%). Naturally, the next question followed, just how much more data could continue to push the performance envelope?
SeaEval had another set of 166k dataset, which seemed to be generated using Llama-3–8B-Instruct instead of GPT-4. I had the intuition that this dataset could be of lower quality, due to the nature of the inference model and judging by the noticeably shorter average response length as compared to SeaEval-26k (which was generated from GPT-4). Nevertheless, I chose the top 25k data points with the longest response token length and combined that with SeaEval-26k dataset. Unsurprisingly, this turned out with a noticeably worse-off performance at 17/49 (34%).
Although I had the idea to refine the 166k dataset responses using ChatGPT-4o, I felt that the whole copying-pasting and wait time for inference would be too tedious. The OpenAI batch API was another option to do it programmatically, but I forwent it due to potential costs (as I wanted the response to be long - which meant higher token costs).
There is a whole realm and recent attention on synthetic data generation, so feel free to dive into the rabbit-hole if you would!
The Last Burst 🔗
As we neared the end of the preliminary round, I decided to focus on the SeaEval-1k and circled back to experiment with some hyperparameters tuning.
Using the same learning_rate, lora_r, and lora_alpha, I iterated with epoch = 2 and epoch = 3, which gave me a score of 24/49 (48%) and 25/49 (51%) respectively. Preliminary, it seemed like there is some correlation between increasing epoch and performance, but to what extent remained to be answered (as I had wanted to reserve my remaining training hours for one final fine-tuning).
In my final fine-tuning, I again used the full SeaEval-26k but increased the epoch from 1 to 2. This eventually netted me my best final score of 27/49 (55%) and hence 2nd place in the preliminary round. However, this came at a cost of ~8 hours of training time (although the training time could potentially be reduced using a higher per_device_train_batch_size as the default is 1, but there is a need to tread this carefully to avoid out-of-memory issue).
TL;DR 🔗
- Dataset quality > quantity - start with 1k and use long response token length as a proxy for quality.
- Experiment with other hyperparameters like
lora_r,lora_alpha,lora_dropout,target_modulesbesidesepochandlearning_rate, but have a systematic plan of tuning. - Increase
per_device_train_batch_sizeto reduce training time but within the limits of available memory (thanks Swee Heng for this tip). - Use the training and evaluation losses as indication of overfitting. It would be even better to monitor your training and evaluation losses (albeit there is no easy way to do this except for monitoring the logs) and cut your ’losses’ (pun-intended) early if you detect overfitting to save your training hours. This is especially if you are training for a high number of
epoch. - Read academic/research papers (if you can and are interested!). One of the best resources is arXiv. You don’t necessary need to understand the details but they can give good intuition and ideas to try.
- Keep a log of hyperparameters and datasets used, and the corresponding model performance for reference.
Grand Finale 🔗
At the Grand Finale, the finalists had to craft our prompts and decide on the temperature and top-P parameters (all within 60 seconds) depending on the nature of each question.
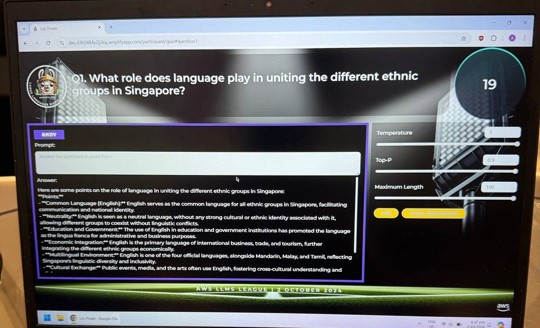
Interface used for the Grand Finale (Note: this was a test question during dry run)
There wasn’t really too much time to meddle with the temperature and top-P given the limited time we had for inference, so I left it at the default of 1 and 0.9. I decided so in view that the questions were largely argumentative rather than factual in nature (more so for question 6 and 7 which tested our models’ on creativity).
Prompt Engineering 🔗
We had a dry run the day before the Grand Finale to familiarise ourselves with the interface and parameters. Given the limited time we had to prompt, get the inference output and potentially re-prompt, the finalists had a consensus to prepare our prompts beforehand so that we can do a simple copying-pasting during the actual Grand Finale.
Being a novice in prompt engineering (and the lack of energy to deep dive into it), I prepared a simple prompt based off some brief research:
You are an expert on Singapore culture and will be judged on your answer.
Answer the question as accurate and comprehensive.
Start with a title and then a short introduction.
Use sub paragraphs and elaborate in details in point forms.
Give as many details and examples as possible.
Sidenote: you could actually ask ChatGPT to suggest a good prompt framework for you, which one of the finalists Chee Hoe did and gotten pretty good results!
The interface we were using for the Grand Finale would automatically append the actual question to the prompt, so we did not have to copy the question into the prompt.
Since we were judged by a LLM (40%), a panel of five experts (40%), and audience (20%), I felt that the most controllable component was the LLM judge. Hence, I had the strategy (and hence the way I crafted my prompt) to focus on generating a long response in hope to maximise the LLM judge’s score. From the preliminary round, it seemed like a LLM judge had the tendency to prefer longer response. I also came across another working paper “Style Outweighs Substance: Failure Modes of LLM Judges in Alignment Benchmarking” which suggested that LLM judges have implicit biasness and prioritise style over factuality.
My strategy mostly worked as I was scored relatively well by the LLM judge, but much less so by the panel of experts. This was expected and I was simply trying to hang on and stay in the game for 3rd place (because I just wanted the nice trophy!).
The turning point came in the final question (the bonus round) which gave double points. It was a question that tested the model’s creativity to come up with an “innovative acronym that captures the essence of Singapore culture”. I had the intuition to amend my prompt slightly, hoping that the response would be more creative and light-hearted, while ensuring that the output format that is not too structured and rigid (i.e. avoid title and sub-paragraphs).
You are an expert on Singapore culture and will be judged on your answer.
Answer the question as accurate and comprehensive.
Come up with an acronym and explain in details.
Be creative and funny.
On the first inference attempt, my model came up with an acronym that was not an actual word. Hence I made the decision to regenerate and it thankfully it came up with an acronym S.A.C.R.E.D that made sense. I felt it had a good connotation when used to describe Singapore! For this question, I think I was judged as 2nd by the LLM judge and 1st from the panel of experts, which pushed me to overall 1st place.
On hindsight, I could have amended my prompt along the lines of: “Come up with an acronym that is an actual word related to Singapore, and explain in details”.
Questions Recap 🔗
To have a sense of how our fine-tuned LLMs were put to the test, here are the seven questions that were asked:
- How has Singapore’s multicultural heritage influenced its modern cuisine, and what are some of the latest unique fusion dishes that have I emerged as a result?
- Describe the significance of the “kampong spirit” in Singapore’s history and explain how it has evolved in today’s urban environment.
- Explain the role of Singlish in Singaporean identity and discuss the government’s stance on its usage in formal and informal settings.
- What has changed in Singapore’s education system lately and how does it shape the country’s cultural values and prepare the future generations?
- Where are the recommended hawker centres in Singapore and its famous dishes for Generation Z?
- Write a memoir about changes you’ve seen in Singaporean commuters over the years. What are the most amusing trends you’ve noticed in 2024?
- Singaporeans are known for their love of acronyms and abbreviations (e.g., “BTO” for “Built to Order”). Can you create an innovative acronym that captures the essence of Singapore culture?
Conclusion 🔗
I had great fun participating in the LLML and I hope this writeup will help future participants have a shorter learning curve and see early success in their fine-tuning efforts. I certainly expect the next round of LLML to be more intense and competitive!
I am by no means an expert in fine-tuning or prompting, and there’s still so much for me to learn. Looking forward to connecting with and learning from many more like-minded people in the AI space!
Special thanks to Gen-C Generative AI Learning Community for hosting the workshop and the AWS team for organizing and facilitating the LLML, and many others who contributed to the success of the workshop and competition!
Till the next Singapore Nationwide AWS Large Language Models League!